Introduction to Tier-1 Data#
What is Tier-1 Data?#
More and more VSC users have computational tasks that make intensive use of large data sets. The Tier-1 Data platform of the VSC enables researchers to store their data close to the computing infrastructure during the active phase of their research projects. Additionally, it gives them tools to manage data in a FAIR and efficient way from start to finish.
The Tier-1 Data platform is based on the open source software iRODS. Researchers can manage data via different clients, such as a command-line interface, a Python API or a web interface.
Tier-1 Data provides four core competencies:
Storage
Data is stored securely in the data centers of KU Leuven. Of each file, two copies are stored: one in the datacenter of Heverlee, and one in the datacenter of Leuven.
Metadata
Data can be described by adding metadata, either on the file or folder level. This metadata can serve multiple purposes:
Provide context to the data
Make data findable via the search interface
Play a role in workflow automation
Metadata can be added manually, but also via automation (e.g. extraction of metadata from file headers) or by using metadata schema’s in the web interface.
Automation
Tier-1 Data has a a Python API and a command-line interface, which can be integrated easily into your existing code and jobscripts. This way, you can easily integrate data movement and data management actions in your existing HPC workflow.
Tier-1 Data’s servers also have event triggers called Policy Enforcement Points (PEPs), which are triggered every time a certain type of action happens (e.g. a user uploads a file). Administrators can define processes that run each time one of these PEPs is triggered. This allows us to work together with users and create powerful, automated workflows that help to save time and prevent human errors.
Secure Collaboration
In Tier-1 Data, you can share data with users and user groups via a system of permissions. Permissions can be managed on file and folder level, allowing for fine-tuned access control. If you have collaborators without a VSC account, data in Tier-1 Data can be shared via the tool Globus.
Tier-1 Data Architecture#
The Tier-1 Data platform is based on the open source software iRODS. The image below shows the high level architecture of the platform:
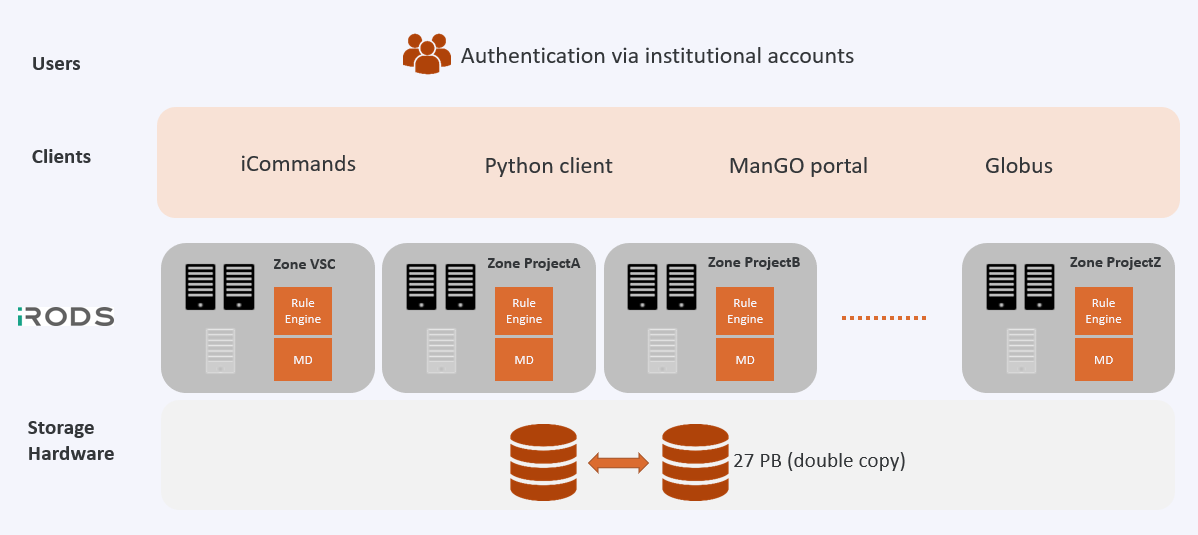
An single installation of iRODS is called a ‘zone’. By default, new projects are created in our general zone ‘VSC’. Separate zones can be created for confidentiality or efficiency reasons for different projects.
Each zone has a Rule engine and an iCAT database, which contains metadata, permissions and an index of all file locations. Inside a zone, each project has their own folder.
The data itself is synchronized on two separate storage systems, each with 27 PB of usable capacity, located at ICTS KU Leuven datacenters in Heverlee and Leuven. The data is protected against calamities at either site by synchronizing it in real-time at hardware level. One system does not function as a backup for the other, so this is no protection against accidental instructions (i.e. user mistakes) to delete data. Snapshots are made at regular intervals (hourly, daily and monthly) in case data needs to be recovered. For data recovery in case of emergency, please contact data@vscentrum.be.
An iRODS zone can be accessed from different systems:
The HPC clusters of the Flemish Supercomputing Center (VSC)
Your laptop
Scientific instruments like scanners and microscopes
From each of these systems, access is facilitated by a variety of clients:
iCommands is a package that gives users a command-line interface to operate on data in iRODS.
The Python-iRODSClient (PRC) is a Python client API that can make a secure connection to iRODS so that you can integrate your iRODS data interactions within your (existing) python programs.
The ManGO Portal: the web front-end for Tier-1 Data, which provides a very user-friendly approach.
Finally, data exchange between zones and externally is possible thanks to Globus. More information can be found in the Globus documentation.
User Access to Tier-1 Data#
If your research group is interested in using Tier-1 Data, you need to request a Tier-1 Data project. This is done by submitting a project application, in which you explain your research, your workflow, and how the capabilities of Tier-1 Data may improve your workflow. Importantly, each collaborator should have a VSC-account.
Unlike Tier-1 Compute applications, Tier-1 Data applications do not have a cut-off date. You can apply for a Tier-1 Data project at any time.
For more information on this procedure, see https://www.vscentrum.be/data.
Users can connect to Tier-1 Data by using different clients from any computer after logging in with their institutional account. For example, VSC users from UAntwerpen will be forwarded to the UAntwerpen login page.
The landing page for all Tier-1 Data clients is our web front-end, the ManGO portal. After logging in, you will get an overview of all zones you have access to. By clicking on ‘Enter portal’, you will go to the ManGO portal for that zone. If you prefer to access Tier-1 Data via a different client, you can find the necessary credentials or code under ‘How to Connect’.
For iCommands, you need a Linux client environment on a linux based operation system (Linux distros or Installing WSL2 on windows) with iCommands installed. This client has been installed on most of our HPC systems.
For the Python programming client (PRC), you need at least an installed Python release and the PRC itself. This suffices for a connection with the default password duration of 60 hours. However, it is also possible to log in with a password of long duration (7 days) if you also have a Linux client environment with iCommands installed.
For more information on how to install and use each client, see the clients section.
Once logged in, Tier-1 Data users can find their group folder at /<zone-name>/home/<project-name>.
This area is shared with and visible to all members of your group, but can be further subdivided in subfolders
with more specific permissions.